The method of generating an English Wikipedia article can be summarized as a multi-document summary of the source document.
Recent studies have revealed that generating English Wikipedia articles can be viewed as a multi-document summarization task. This approach involves using extractive methods to identify key information and then applying a neural abstraction model to craft the final text. To handle long sequences effectively, we developed a decoding-only architecture, which outperforms traditional encoder-decoder models in processing extensive content. Our experiments show that this model can generate fluent, coherent paragraphs and even full Wikipedia articles. When tested with reference materials, it successfully extracts factual details, as confirmed by ROUGE scores, complexity metrics, and human evaluations.
Sequence-to-sequence frameworks have been widely used for tasks like machine translation and news summarization. In previous work, these models were trained on single documents, often using the first sentence or entire article as input. However, end-to-end training requires large parallel datasets, making it challenging without sufficient labeled examples. This limitation has led researchers to explore alternative approaches, especially for more complex tasks such as multi-document summarization.
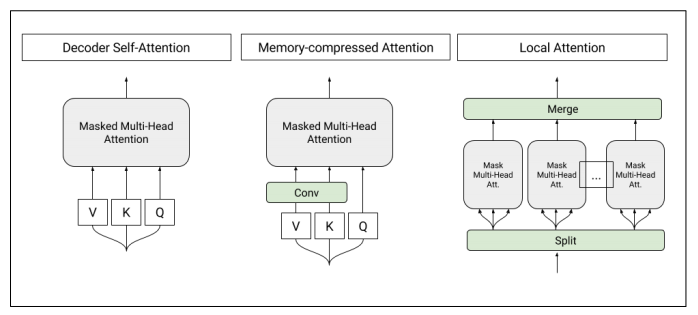
Figure 1: Architecture of self-attention layers used in the T-DMCA model. Each attention layer processes a sequence of characters and outputs a similar-length sequence. Left: Original self-attention mechanism. Middle: Memory-compressed attention reduces the number of keys and values. Right: Partial attention segments the sequence into smaller parts, which are then combined for the final output.
Traditional summarization research has focused on extractive methods, where sentences are selected from the input rather than generated. While effective for short texts, these techniques struggle with longer, multi-source documents. The lack of large labeled datasets has also limited the development of abstract summarization models. In contrast, our work explores a new approach by treating Wikipedia generation as a supervised learning task, where the input includes multiple related documents and the output is a structured summary.
For the first time, we attempted to generate the beginning or citation section of a Wikipedia article based on reference texts. We modified the Transformer architecture by using only a decoder, which allows better handling of long sequences. Compared to RNNs and standard Transformer models, our approach showed improved performance. The results demonstrated that our model could produce complete, well-structured Wikipedia articles.
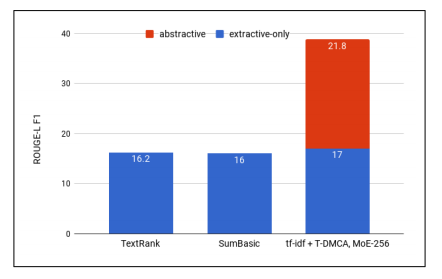
Figure 2: ROUGE-L F1 scores for various extraction methods, with the best performance achieved by the tf-idf-T-DMCA combination.
Other datasets for neural abstractive summarization include the English Gigaword corpus, which was used to train early models. However, these tasks often resemble sentence-level prediction rather than full summarization. More recent datasets, such as those derived from CNN and Daily Mail, offer more complex challenges but suffer from limited sample sizes and inconsistent annotation criteria.
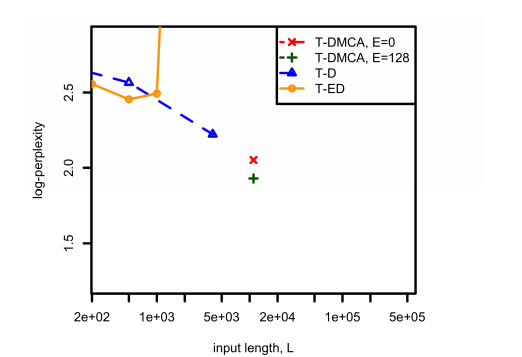
Figure 3: Comparison of model performance on the tf-idf extraction problem across different architectures. Here, E represents the size of the expert-of-experts component in the T-DMCA model.
In our study, we trained on a multi-document summarization task using Wikipedia data. As shown in Table 1, the input and output lengths vary significantly depending on the article. Unlike typical summaries, Wikipedia content is usually longer and more structured, requiring models to handle complex, multi-sentence outputs.

Table 1: Input/output sizes and unigram recall rates for summary datasets.
The ROUGE-1 score in Table 1 indicates how much of the output overlaps with the input. Higher scores suggest easier extractive tasks, while lower scores imply more abstract generation is needed. Our dataset had a score of 59.2, which is relatively low compared to other datasets, suggesting that pure extractive methods may not be ideal for this task.
Many studies have explored the use of Wikipedia for machine learning tasks, including question answering and text generation. One of the closest works to ours is Sauper and Barzilay’s (2009) approach, which used templates to generate articles. However, their work was limited to two categories, whereas we aim to cover all types of Wikipedia entries. Additionally, we incorporate references directly into the “References†section of the article, enhancing its credibility and completeness.

Figure 4: Predictions from different models for the same sample. As complexity decreases, the model output improves in terms of fluency, fact accuracy, and narrative structure. The T-DMCA model provides a concise version of the Wikipedia entry, highlighting key facts about the firm's location, formation, and decline.

Figure 5: Translation from Transformer-ED, L = 500. During manual evaluation, we noticed that the model sometimes translated names into other languages, such as translating "Rohit Viswanath" into Hindi. Although we did not test translations systematically, many of them were accurate and not present in the original Wikipedia text. This suggests that the model might be learning language patterns beyond just copying from sources.
Overall, our research demonstrates that generating Wikipedia articles can be framed as a multi-document summarization task. Using a two-stage framework—first extracting relevant content, then abstracting it—we achieved high-quality results. The decoding-only model significantly outperformed traditional architectures when dealing with long sequences, enabling the creation of coherent and informative Wikipedia entries from diverse sources. Future work will focus on improving the extraction stage and refining the abstraction process for even better performance.
Solar Charge Controller Pwm,Outdoor Solar Charge Controller,Manual Solar Charge Controller,Intelligent Solar Charge Controller
GuangZhou HanFong New Energy Technology Co. , Ltd. , https://www.gzinverter.com