The method of generating an English Wikipedia article can be summarized as a multi-document summary of the source document.
Recent studies have demonstrated that generating English Wikipedia articles can be viewed as a multi-document summarization task. This process typically involves two key stages: first, using extractive methods to identify the most salient information from the source documents, and then applying a neural abstraction model to generate a coherent, full-length article. For the abstraction model, we introduced a decoding-only architecture capable of handling extremely long sequences—far beyond what traditional encoder-decoder models can manage. Our experiments show that this approach can produce smooth, well-structured paragraphs and even complete Wikipedia entries.
Sequence-to-sequence frameworks have been widely successful in tasks like machine translation. More recently, they have also been applied to single-document abstractive summaries, particularly for news articles. In prior work, these models were trained end-to-end, often using only the first sentence or the entire article as input, with the goal of predicting a reference summary. However, such an approach requires large amounts of parallel data, as language understanding is crucial for generating fluent and accurate summaries.
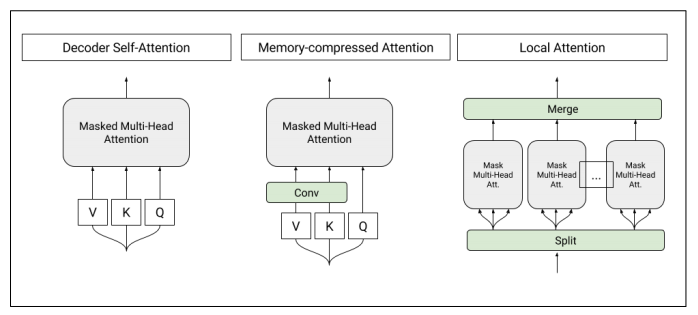
Figure 1: Architecture of self-attention layers used in the T-DMCA model. Each attention layer takes a sequence of characters as input and produces a sequence of similar length as an output. Left: Original self-attention used in the converter decoder. Medium: Memory-compressed attention layers, reducing the number of keys/values. Right: Partial attention to segment the sequence into smaller subsequences, which are then combined to form the final output.
Instead of focusing on single-document summaries, we explored the challenge of multi-document summarization, where the input consists of multiple related documents, and the goal is to produce a refined, concise summary. Previous research has mainly focused on extractive approaches, selecting sentences or phrases from the input rather than generating new content. However, abstractive methods face limitations, partly due to the lack of large-scale labeled datasets.
In our study, we treated English Wikipedia as a supervised learning task, where the input includes a collection of Wikipedia topics (article titles) and non-Wikipedia references, and the output is the corresponding article text. For the first time, we attempted to generate the opening section or citations of a Wikipedia article based on external reference texts. We also adapted the Transformer architecture by using only a decoder, which proved more effective for longer input sequences compared to RNNs and standard Transformer encoder-decoder models. The results showed that our improvements enabled the generation of full Wikipedia articles.
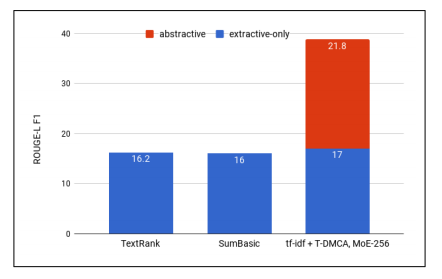
Figure 2: ROUGE-L F1 scores for various extraction methods, with the abstract model showing the best performance when combined with tf-idf-T-DMCA.
Other datasets have also been used in neural abstractive summarization. For example, Rush et al. (2015) used the English Gigaword corpus, which contains news reports from multiple publishers. Their model was trained to generate summaries, but the task was more akin to sentence interpretation rather than true summarization. Using ROUGE and human evaluation, they found that an attention-based RNN model performed well on this task.
In 2016, Nallapati et al. created a dataset by modifying the Daily Mail and CNN news stories, adding highlights as summaries. This task is more challenging than title generation because the highlights may draw from different parts of the article. However, the dataset has fewer parallel samples (310k vs. 3.8M), making it harder to train models. Additionally, the criteria for creating highlights are unclear, and there are significant differences in writing styles between the two sources.
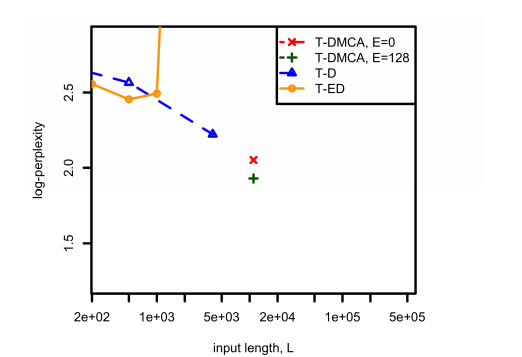
Figure 3: Comparison of complexity and the relationship between L in the tf-idf extraction problem across different model architectures. E represents the size of the expert-of-experts for T-DMCA.
In our research, we also trained on neural abstractive models, but within the context of Wikipedia’s multi-document summarization. As shown in Table 1, the input and output sizes vary significantly depending on the article. Abstracts in Wikipedia are usually multiple sentences or even paragraphs, written in a consistent style. However, the input documents can come from diverse sources with varying formats and styles.

Table 1: Input/output size and unigram recall for summary datasets.
Table 1 also shows the ROUGE-1 score for each dataset, which measures the overlap of unigrams between the input and output. A higher score indicates that the output is more likely to be extracted directly from the input. For instance, if the output is entirely copied from the input, the score would be 100%. Compared to other datasets with scores of 76.1 and 78.7, our score of 59.2 suggests that our method is less suitable for pure extractive summarization.
Tasks involving Wikipedia have attracted significant research interest, including question answering, information extraction, and text generation in structured data. One of the closest works to ours is Sauper and Barzilay (2009), who generated articles using a template-based approach from reference documents. However, their work was limited to two categories, while we use all types of Wikipedia articles. They retrieved reference documents via search engines, similar to our approach, but we also include the results in the "References" section of the Wikipedia page.

Figure 4: Prediction results from three different models (tf-idf extraction and combined corpus) compared to the actual Wikipedia facts.
As seen in Figure 4, the model's output improves in terms of fluency, factual accuracy, and narrative complexity as the input complexity decreases. The T-DMCA model, in particular, offers a more concise alternative to the Wikipedia version, highlighting key facts such as the location, formation, rise, and decline of a law firm.

Figure 5: Translation from Transformer-ED, L = 500.
During manual inspection of the model outputs, we observed an unexpected side effect: the model sometimes translated English names into other languages, such as translating "Rohit Viswanath" into Hindi (see Figure 5). Although we did not systematically evaluate translations, we found them to be mostly correct and not present in the original Wikipedia article. We also confirmed that translations were not simply copied from the source, as some examples contained incorrect target language outputs, such as English to Ukrainian.
Our research demonstrates that generating Wikipedia articles can be framed as a multi-document summarization problem, supported by a large parallel dataset and a two-stage framework combining extraction and abstraction. The initial extraction stage significantly impacts the final performance, suggesting that further refinement could yield better results. In the abstraction phase, we introduced a novel decoding-only model capable of handling very long sequences, outperforming traditional encoder-decoder architectures. This improvement allows us to generate coherent and informative Wikipedia articles based on multiple references.
Solar Panel Cleaning Tools,Solar Cleaning Brush,Solar Panel Cleaning Machine,Solar Panel Cleaning System Tools
GuangZhou HanFong New Energy Technology Co. , Ltd. , https://www.gzinverter.com