Analyze over-fitting and under-fitting of training sets
Before we dive into the formal definitions of these two key concepts, let’s start with a relatable story. Imagine you want to learn English from scratch, but you’ve heard that Shakespeare is one of the greatest British writers. Naturally, you head to the library and start reading his works, thinking this is the best way to master the language. After a year of intense study, you walk out of the library and step onto the streets of New York. You approach the first person you see and say, “Hey, let the light be with you!†The person looks at you in confusion. You mutter “neuropathy†under your breath, trying again: “Dear lady, how elegant is today?†This time, the person runs away. After three failed attempts, you’re frustrated and exclaim, “Oh, what a regret, how sad!†But here’s the problem—you’ve made one of the most fundamental mistakes in modeling: overfitting.
In data science, an overfit model is characterized by high variance and low bias. It performs exceptionally well on the training data but fails to generalize to new, unseen data. To better understand this, think of it like learning English through Shakespeare’s works only. You memorize every line, but when you try to speak in real-life situations, people don’t understand you. Why? Because your model has become too dependent on the specific examples in the training set and can't adapt to new contexts. It's like a student who memorizes textbook questions but can't solve any real-world problems.
Now, let’s break down what variance and bias really mean. Variance refers to how much the model’s predictions change based on the training data. If you simply memorize Shakespeare’s words, your model will have high variance—it becomes overly sensitive to the specific data it was trained on. If instead, you read J.K. Rowling’s books, the model would look completely different. When applied to a new test set, such as real conversations in New York, the model fails because it lacks flexibility.
Bias, on the other hand, represents the assumptions the model makes about the data. In our English example, if you assume that only certain phrases are important, you might miss the broader structure of the language. While low bias sounds good (because it suggests less assumption), it can lead to issues if the training data isn’t comprehensive enough. No dataset is perfect—there’s always noise, and you can’t guarantee that your training data covers everything. So, even if you're not biased, you still need to ensure your model can handle the unknown.
In short, bias relates to how much the model ignores the data, while variance reflects how much it depends on it. There's always a trade-off between the two, and finding the right balance is crucial for building a robust model. These concepts apply to all types of models, from simple to complex, and are essential for any data scientist to understand.
So, what happens when a model has low variance and high bias? That’s called underfitting. Unlike overfitting, where the model is too focused on the training data, underfitting means the model doesn’t learn enough from the data. Let’s go back to the English example. This time, you decide to use the entire script of "Friends" as your training data. But instead of learning all the dialogues, you make a rule: only sentences starting with “the,†“be,†“to,†“of,†and “a†are important. You ignore the rest, thinking this will make the model more efficient. After months of training, you go to New York again, but your English is still hard to understand. You’ve learned some basic phrases, but you lack the grammar and structure needed to communicate effectively. Your model is too rigid, and it fails to capture the true essence of the language.
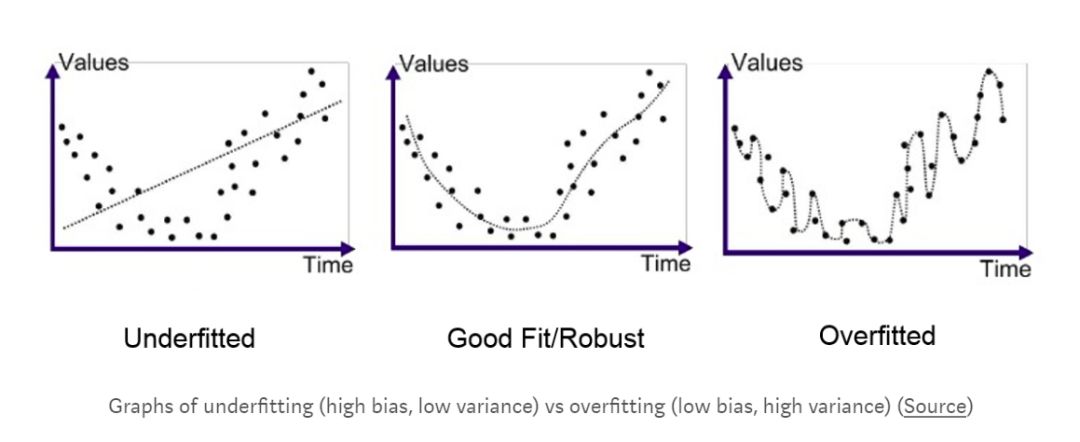
The lesson here is clear: too much focus on the data leads to overfitting, while too little leads to underfitting. The solution? A validation set. In the previous example, we only used a single training and test set. But that’s not ideal. What if we could test our model before putting it into real-world use? That’s where the validation set comes in. It acts as a simulation test, allowing us to evaluate and refine our model before deploying it.
After two failed attempts, we decided to take a smarter approach. This time, we used both Shakespeare and Friends as training data. More importantly, we introduced a validation set. Instead of going straight to the streets of New York, we practiced with a group of friends, using their feedback as a form of validation. Each week, we adjusted our model based on what we learned. Eventually, we were confident enough to face the real test—and this time, it worked! We were able to communicate naturally, thanks to the insights gained during the validation phase.
This example shows how powerful validation can be. In real-world data science, we often use cross-validation, which involves splitting the data into multiple subsets. This ensures that the model is tested thoroughly and isn’t just optimized for a single dataset. Cross-validation helps prevent both overfitting and underfitting, making the model more reliable and adaptable.
Data science may seem complex, but it’s built on simple, foundational ideas. Understanding concepts like overfitting, underfitting, bias, and variance is key to building effective models. By applying these principles, we can create systems that perform well in real-world scenarios. Whether it's learning a language or training a machine learning model, the same rules apply: find the right balance, validate your results, and keep refining your approach.
The Flum Float Disposable Vape provides users with approximately 3000 puffs and is made with 5% salt nicotine e-juice. It features a cylindrical design and uses a draw-activation firing mechanism for quick and easy vaping. Choose from any one of Flum Vapor's tasty flavors and find out what's your favorite.
Specifications:
8.0 mL per e-cigarette
5% nicotine by weight
Approximately 3000 puffs per device
Made with salt nicotine
Pre-filled
Pre-charged
Made in China
Draw-activation firing mechanism
Package Contents:
1 X Flum Float Disposable E-Cigarette
Flum Disposable Vape,Flum Float Vape,Flum Disposable,flum vape,flum vape pen.
Shenzhen Ousida Technology Co., Ltd , https://en.osdvape.com